KMeans Clustering
Contents
0. Motivation
KMeans clustering has been one of the most popular unsupervised machine learning models for exploring latent trends in datasets. We explored this approach with the assumption that clustering would shed light on underlying patterns of tracks regarding 1) how they are similar (either within, or outside of the scheme of genres), and 2) how they are grouped together into playlists by users. Specifically, we explored this centroid-base algorithm on audio features. In short, the clustering process groups tracks by minimizing their differences by audio features, with respect to the number of centroids defined.
1. Strategy
1.1 Evaluation and Prediction
For consistency and comparative purpose of the current project, we defined evaluation and prediction for models before the models were built. Regardless of the size of dataset at the stage of exploration, we train-test split our dataset so that 20% of each playlist were put aside as the test set. Within training, 20% of each playlist were put aside for validation. For clustering prediction, the test set was only used in final step after model tuning. Our models were evaluted using R-Precision, Normalized Discounted Cumulative Gain (NDCG).
1.2 KMeans Clustering
Tracks were clustered based on the following audio features: acousticness, danceability, energy, instrumentalness, key, liveness, loudness, speechiness, tempo, time signature and valence. Audio features were retrieved from the Spotify API. All features were standardized before clustering to control for range of variances.
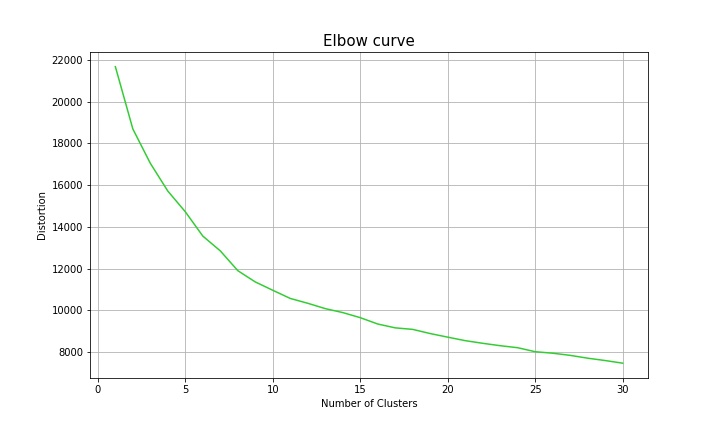
The number of clusters used was suggested by distortion curves. In particular, we defined distortion as the sum of within-cluster
squared distances. The image below demonstrates the distortion curve for clustering on 100 playlist subset. In general,
we failed to observe an elbow turn of distortion curves in the current project. We approached our clustering model with k = 8.
We recorded all cluster labels assigned to each track. In addition, centroids were ordered based on their distances to one another. Within-cluster occurrence was computed for both artist and track upon clustering, the resulting prediction data frame served as the basis of our prediction model.
An example prediction data frame:
| Playlistid | Trackid | Track_uri | Artist_Name | Track_Name | artist_genres | artist_popularity | cluster_label | mode_artist | mode_track | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 256979 | 18 | spotify:track:0qOnSQQF0yzuPWsXrQ9paz | Gym Class Heroes | Stereo Hearts (feat. Adam Levine) - feat. Adam... | ['dance pop', 'emo', 'pop punk', 'pop rap'] | 64.0 | 2 | 3 | 2 |
| 1 | 38828 | 10 | spotify:track:0qOnSQQF0yzuPWsXrQ9paz | Gym Class Heroes | Stereo Hearts (feat. Adam Levine) - feat. Adam... | ['dance pop', 'emo', 'pop punk', 'pop rap'] | 64.0 | 2 | 3 | 2 |
| 2 | 208779 | 7 | spotify:track:77ZdAoTHYoF6Umo76HFD4m | Gym Class Heroes | The Fighter - feat. Ryan Tedder | ['dance pop', 'emo', 'pop punk', 'pop rap'] | 64.0 | 2 | 3 | 1 |
| 3 | 117841 | 20 | spotify:track:5zGqTc1WQUe8XqqdnrpKTV | Rodney Atkins | Farmer's Daughter | ['contemporary country', 'country', 'country r... | 66.0 | 2 | 1 | 1 |
| 4 | 61388 | 36 | spotify:track:1D9XLqQp2YYiOxrr5KLb8K | Drake | Under Ground Kings | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 3 | 7 | 1 |
1.3 Prediction Model
Our final prediction model was constructed in two steps. The original model was built and evaluated on the validation set, upon which we investigated the clustering data frames and predictions. We “tuned” our updated model (the final model) by adding an extra prediction step.
1.3.1 Original Model
The original model was based on the assumption that tracks assigned to a cluster would be similar to each other, and that the distances between clusters capture similarities between clusters, or groups of tracks.
For each unique playlist id acquired from the validation set, we subsetted the existing data on the playlist from the prediction data frame. Cluster labels for the subset was counted for occurance, ordered descendingly, and returned as a list. We populated the list based on pre-ordered between-centroid distances; the idea is to generate predictions from the most-likely to least-likely clusters. For each cluster, we generated predictions based on, first, the most popular artist, and second, the most popular track within the cluster. Prediction terminates when we have 15 times the actual number of tracks existing in the validation set.
Below is a demonstration of prediction using the original model. The source code could be accessed at our GitHub repository.
#demo for playlist number 20043
example = prediction_cluster[prediction_cluster.Playlistid == 20043]
#Prediction data frame trained on training set
example.head()
| Playlistid | Trackid | Track_uri | Artist_Name | Track_Name | artist_genres | artist_popularity | cluster_label | mode_artist | mode_track | |
|---|---|---|---|---|---|---|---|---|---|---|
| 23 | 20043 | 20 | spotify:track:1vvnYpYEMVB4aq9I6tHIEB | J. Cole | 4 Your Eyez Only | ['conscious hip hop', 'hip hop', 'pop', 'pop r... | 84.0 | 7 | 11 | 1 |
| 134 | 20043 | 0 | spotify:track:6F609ICg9Spjrw1epsAnpa | Drake | Controlla | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 7 | 51 | 2 |
| 138 | 20043 | 3 | spotify:track:6bqtKURdSWkInAJHDkuaL0 | Drake | I'm The Plug | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 7 | 51 | 2 |
| 144 | 20043 | 2 | spotify:track:7jslhIiELQkgW9IHeYNOWE | Drake | Big Rings | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 7 | 51 | 3 |
| 159 | 20043 | 8 | spotify:track:124NFj84ppZ5pAxTuVQYCQ | Drake | Take Care | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 7 | 51 | 3 |
#predict for demo
pred_example = predict_cluster.cPredict(prediction_cluster, 20043, orderRankc, val[val.Playlistid == 20043])
#visualize tracks predicted for the example data set
dfpred_example = prediction_cluster[prediction_cluster.Track_uri.isin(pred_example)]
dfpred_example.head()
| Playlistid | Trackid | Track_uri | Artist_Name | Track_Name | artist_genres | artist_popularity | cluster_label | mode_artist | mode_track | |
|---|---|---|---|---|---|---|---|---|---|---|
| 18 | 46047 | 0 | spotify:track:62vpWI1CHwFy7tMIcSStl8 | J. Cole | No Role Modelz | ['conscious hip hop', 'hip hop', 'pop', 'pop r... | 84.0 | 7 | 11 | 4 |
| 19 | 153929 | 65 | spotify:track:62vpWI1CHwFy7tMIcSStl8 | J. Cole | No Role Modelz | ['conscious hip hop', 'hip hop', 'pop', 'pop r... | 84.0 | 7 | 11 | 4 |
| 20 | 22204 | 14 | spotify:track:62vpWI1CHwFy7tMIcSStl8 | J. Cole | No Role Modelz | ['conscious hip hop', 'hip hop', 'pop', 'pop r... | 84.0 | 7 | 11 | 4 |
| 21 | 190503 | 7 | spotify:track:62vpWI1CHwFy7tMIcSStl8 | J. Cole | No Role Modelz | ['conscious hip hop', 'hip hop', 'pop', 'pop r... | 84.0 | 7 | 11 | 4 |
| 22 | 219212 | 10 | spotify:track:3FWR4iiUUPHIK7OpiEgh8J | J. Cole | Lost Ones | ['conscious hip hop', 'hip hop', 'pop', 'pop r... | 84.0 | 7 | 11 | 1 |
218 rows × 10 columns
#true validation set for demo
true_example = val[val.Playlistid == 20043]
true_example.head()
| Playlistid | Trackid | Artist_Name | Track_uri | Track_Name | Album_Name | Track_Duration | acousticness | artist_genres | artist_popularity | ... | explicit | instrumentalness | key | liveness | loudness | mode | speechiness | tempo | time_signature | valence | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 428 | 20043 | 61 | Bryson Tiller | spotify:track:3Jrs7cC2OJNlNSy9VnDOMZ | Somethin Tells Me | True to Self | 194266 | 0.035600 | ['hip hop', 'indie r&b', 'pop', 'pop rap', 'r&... | 76.0 | ... | True | 0.000000 | 5.0 | 0.1070 | -7.197 | 0.0 | 0.2260 | 90.002 | 4.0 | 0.4340 |
| 429 | 20043 | 62 | A Boogie Wit da Hoodie | spotify:track:1f5cbQtDrykjarZVrShaDI | Drowning (feat. Kodak Black) | The Bigger Artist | 209269 | 0.501000 | ['hip hop', 'pop', 'rap', 'southern hip hop', ... | 78.0 | ... | True | 0.000000 | 5.0 | 0.1170 | -5.274 | 0.0 | 0.0568 | 129.014 | 4.0 | 0.8140 |
| 377 | 20043 | 10 | Drake | spotify:track:4Kz4RdRCceaA9VgTqBhBfa | The Motto | Take Care | 181573 | 0.000107 | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | ... | True | 0.000061 | 1.0 | 0.1110 | -8.558 | 1.0 | 0.3560 | 201.800 | 4.0 | 0.3900 |
| 393 | 20043 | 26 | Nicki Minaj | spotify:track:73DydXpS6xXmsFNvYrSpIQ | Favorite | The Pinkprint | 242946 | 0.613000 | ['dance pop', 'hip pop', 'pop', 'pop rap', 'rap'] | 90.0 | ... | True | 0.000057 | 4.0 | 0.0911 | -7.172 | 0.0 | 0.0408 | 103.038 | 4.0 | 0.0635 |
| 395 | 20043 | 28 | Nicki Minaj | spotify:track:7gKIt3rDGIMJDFVSPBnGmj | Super Bass | Pink Friday | 200013 | 0.290000 | ['dance pop', 'hip pop', 'pop', 'pop rap', 'rap'] | 90.0 | ... | True | 0.000003 | 11.0 | 0.5030 | -4.302 | 1.0 | 0.1960 | 127.033 | 4.0 | 0.6390 |
11 rows × 22 columns
The takeaway from the original is that clustering of audio features does not necessarily capture the genres of tracks. Whereas our demonstration shows that clustering generates similar songs that the actual validation set holds, for playlists that are more diverse, this is not necessarily the same. To account for this deficiency of the original model, we added a step to prioritize track prediction based on artists.
1.3.2 Final Model
To improve our model performance, we prioritized prediction based on artist occurance in a playlist before using the clustering results. Before we start filling out the prediction list based on cluster similarities, we ranked artists based on their occurrence in the training data for each individual playlist. Specifically, we predicted songs for artists that appeared 3 times or more, with the most popular ones first. If the prediction list is not then filled, we moved onto the original clustering prediction procedure. This model was directedly tested on test sets for final report. However, for demonstration purpose, we output the prediction on validation set below, with respect to the same example dataset.
#predict for demo using updated model
pred_example_updated = predict_cluster_updated.cPredict(prediction_cluster, 20043, orderRankc, val)
dfpred_example_updated = prediction_cluster[prediction_cluster.Track_uri.isin(pred_example_updated)]
dfpred_example_updated.head()
| Playlistid | Trackid | Track_uri | Artist_Name | Track_Name | artist_genres | artist_popularity | cluster_label | mode_artist | mode_track | |
|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 61388 | 36 | spotify:track:1D9XLqQp2YYiOxrr5KLb8K | Drake | Under Ground Kings | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 3 | 7 | 1 |
| 5 | 153929 | 33 | spotify:track:31Q9ZTF9x81BDonlObCbvP | Drake | Forever | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 3 | 7 | 1 |
| 6 | 153929 | 43 | spotify:track:75L0qdzRnhwV62UXoNq3pE | Drake | Up All Night | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 3 | 7 | 2 |
| 7 | 230183 | 8 | spotify:track:75L0qdzRnhwV62UXoNq3pE | Drake | Up All Night | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 3 | 7 | 2 |
| 8 | 155081 | 6 | spotify:track:6cT5orvyKqwghJp6KB9vG0 | Drake | Furthest Thing | ['canadian hip hop', 'canadian pop', 'hip hop'... | 100.0 | 3 | 7 | 1 |
235 rows × 10 columns
2. Results
Comparisons of the original and updated models were tested on 100, 10k and the full dataset ($N_{unique} =27016$).
- 100 Subset
- Validation Score - Original Model
- R-Precision: 3.61%
- NDCG: 3.78%
- Total Average: 3.70%
- Test Score - Final Model
- R-Precision: 7.75%
- NDCS: 11.41%
- Total Average: 9.58%
- Validation Score - Original Model
- 10k Subset
- Validation Score - Original Model
- R-Precision: 2.99%
- NDCG: 4.29%
- Total Average: 3.64%
- Test Score - Final Model
- R-Precision: 11.82%
- NDCS: 13.31%
- Total Average: 12.56%
- Validation Score - Original Model
- Full Dataset
- Validation Score - Original Model
- R-Precision: 3.82%
- NDCG: 1.91%
- Total Average: 1.11%
- Test Score - Final Model
- R-Precision: 11.92%
- NDCS: 13.27%
- Total Average: 12.59%
- Validation Score - Original Model
3. Conclusion
Comparisons between models suggested that our final model improved considerably on performance. However, it is important to note that our final model is essentially a hybrid of artist-based prediction and cluster-based prediction. It is possible that some prediction process was never moved onto the cluster-based stage. Therefore, it is important to further investigate the effectiveness of each step of our final model. In addition, our current project only investigated K-Means clustering, a centroid-based algorithm; in the future, we can explore other clustering algorithms such as density-based DBSCAN to compare model performance. Future work should also investigate clustering with artist features, and even lyrics features. We posit that clustering with audio features would be maximize when we have a large dataset, however, there would be a limit posed by the limitation in audio features to capture uniqueness and characteristics of tracks.
Source Code: https://github.com/phoebewong/spotify-teamNPK/blob/master/src