k-NN Collaborative Filtering
Contents
The following notebook illustrates our k-NN collaborative filtering approach (uses as our baseline model) that uses track co-occurrence in playlists to recommend tracks to playlists.
0. Motivation
In order to recommend relevant songs to playlists, it is natural to think about songs that are in a similar playlist but not currently in our target playlist.
Our k-NN collaborative filtering modeling approach looks at playlists that share similar tracks (i.e., if the two playlists have a high number of overlapping tracks) and recommend songs that are in the similar playlists but not in the target playlist.
0.1 Strategy
To compute prediction set per playlist, our model does the following:,
-
The model finds k nearest neighbor playlists of our target playlist (measured by cosine distance between playlists).
-
From the k-NN playlists, the model then build the recommendation by recommending tracks that are in the neighbor playlists but not in the target playlist, starting from the most similar playlist. It will stop building the recommendation list until it reaches the pre-determined length (test set size * 15 for each playlist)
1. Data Processing
1.1 Train-test split
We did a stratified splitting of the data (by Playlistid) into training and test set by 80-20. Stratified splitting ensures that we have the right proportion of train and test for playlists of different lengths.
train.shape, test.shape
((1970, 28), (616, 28))
1.2 Binary Sparse Matrix
We used the training set to create a binary sparse matrix with 100 playlists and 1534 unique songs. Each row represents tracks that are in the playlist (1) or not (0). As you can imagine, it is a sparse matrix, because one playlist only has maximum of 350 songs in our dataset, while we have 1534 unqiue songs in the matrix.
We then transformed the matrix to a Compressed Sparse Row matrix from scipy and fit a 5-nearest-neighbor model (using cosine as distance metric and brute-force search).
co_mat.shape
(100, 1534)
Below shows the few rows of the matrix.
co_mat.head()
| Track_uri | spotify:track:00LfFm08VWeZwB0Zlm24AT | spotify:track:00qOE7OjRl0BpYiCiweZB2 | spotify:track:01a0J96fRD91VnjQQUCqMK | spotify:track:01iyCAUm8EvOFqVWYJ3dVX | spotify:track:027h5P3kCyktHv9dpHUBBS | spotify:track:02M6vucOvmRfMxTXDUwRXu | spotify:track:03L2AoiRbWhvt7BDMx1jUB | spotify:track:03LpkqucyYKcYclDs8HuxO | spotify:track:03fT3OHB9KyMtGMt2zwqCT | spotify:track:03tqyYWC9Um2ZqU0ZN849H | ... | spotify:track:7yFMhCJOsH7khgpdnyrZAZ | spotify:track:7yHEDfrJNd0zWOfXwydNH0 | spotify:track:7ySUcLPVX7KudhnmNcgY2D | spotify:track:7yfg0Eer6UZZt5tZ1XdsWz | spotify:track:7yq4Qj7cqayVTp3FF9CWbm | spotify:track:7yyRTcZmCiyzzJlNzGC9Ol | spotify:track:7zBPzAjKAqQpcv8F8GCq5s | spotify:track:7zWj09xkFgA9tcV6YhfU6q | spotify:track:7zbq8RT5Kd3ExOGVTiUQbR | spotify:track:7zxRMhXxJMQCeDDg0rKAVo |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Playlistid | |||||||||||||||||||||
| 430 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 622 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1990 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2259 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2535 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 1534 columns
2. Model Performance
2.1 Metrics
We used the following metrics to evaluate our model, based on Spotify RecSys rules
- R-precision: the number of retrieved relevant tracks divided by the number of known relevant tracks (i.e., the number of withheld tracks). This metric rewards total number of retrieved relevant tracks (regardless of order).
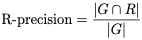
- NDCG: Discounted cumulative gain (DCG) measures the ranking quality of the recommended tracks, increasing when relevant tracks are placed higher in the list. Normalized DCG (NDCG) is determined by calculating the DCG and dividing it by the ideal DCG in which the recommended tracks are perfectly ranked.
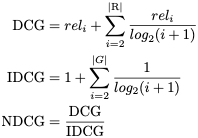
2.2 Model Test-Set Performance
| Data | R-Precision | NDCG | Average of the two metrics |
|---|---|---|---|
| Test set of 100 playlists | 0.077025 | 0.080346 | 0.078685 |
3. Conclusion
We achieved a 0.07 R-precision score and 0.08 NDCG score with our baseline k-NN collaborative filtering model. The current model only consider track co-occurence between playlists, we are curious to know if the model will improve if audio features are added.
https://github.com/phoebewong/spotify-teamNPK/blob/master/src